【MySQL】二十、MySQL数据库生产环境应用经验分享(四)
本文主要介绍MySQL数据库的在生产环境的使用经验分享
8 数据库无法连接故障的定位,Too many connections
经常会遇到的一个问题就是数据库无法连接的问题,看到的信息往往是”Error1040(HY000): Too many connections”,这个时候就是说数据库的连接池里已经有太多的连接了,不能再跟你建立新的连接了。
数据库自己其实是有一个连接池的,你的每个系统部署在一台机器上的时候,那台机器上部署的系统实例/服务实例自己也有一个连接池,你的系统每个连接Socket都会对应着数据库连接池里的一个连接Socket。
所以当数据库告诉你Too many connections的时候,就说他的连接池的连接已经满了,你业务系统不能跟他建立更多的连接了。
曾经在一个生产案例中,数据库部署在4GB的大内存物理机上,机器配置各方面都很高,然后连接这台物理机的Java系统部署在2台机器上,Java系统设置的连接池的最大大小是200,也就是说每台机器上部署的Java系统,最多跟MySQL数据库建立200个连接,一共最多建立400个连接,如下图
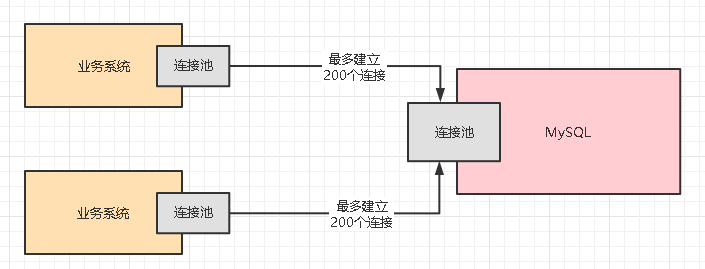
但是这个时候如果MySQL报异常说Too many connections,就说明目前MySQL甚至都无法建立400个网络连接?
于是检查了一下MySQL的配置文件,my.cnf,里面有一个关键的参数是max_connections,就是MySQL能建立的最大连接数,设置的是800。
明明设置了MySQL最多可以建立800个连接,为什么两台机器要建立400个连接都不行呢?这个时候我们可以用命令查看一下:
1 | show variables like 'max_connections' |
当时MySQL仅仅只是建立了214个连接而已,所以猜测是不是MySQL根本不管我们设置的那个max_connections,就是直接强行把最大连接数设置为214了?于是我们可以去检查一下MySQL的启动日志,可以看到如下的字样:
1 | Could not increase number of max_open_files to more than msqld(request:65535) |
所以说,看看日志就很清楚了,MySQL发现自己无法设置max_connections为我们期望的800,只能强行限制为214了。
这是为什么呢?简单来说,就是因为底层的linux操作系统把进城可以打开的文件句柄数限制为了1024了,导致MySQL最大连接数是214。怎么解决这个问题呢?
其实就是一条命令:
1 | ulimit -HSn 65535 |
然后就可以用如下命令检查最大文件句柄数是否被修改了
1 | cat /etc/security/limits.conf |
如果都修改好了之后,可以在MySQL的my.cnf里确保max_connections参数也调整好了,然后可以重启服务器,然后重启MySQL,这样的话,linux的最大文件句柄就会生效了,MySQL的最大连接数也会生效了。
然后此时再尝试业务系统去连接数据库就没问题了。
但是为什么linux的文件句柄数量数被限制了,MySQL最大连接数就被限制了呢?
其实这个是MySQL源码内部写死的,他在源码中就是有一个计算公式,算下来就是如此罢了。
9 线上数据库不确定性的性能抖动优化实践
我们平时在数据库里执行的更新语句,实际上都是从磁盘上加载数据页到数据库内存的缓存页里,接着就直接更新内存里的缓存页,同时还更新对应的redo log写入一个buffer中,如下图所示:
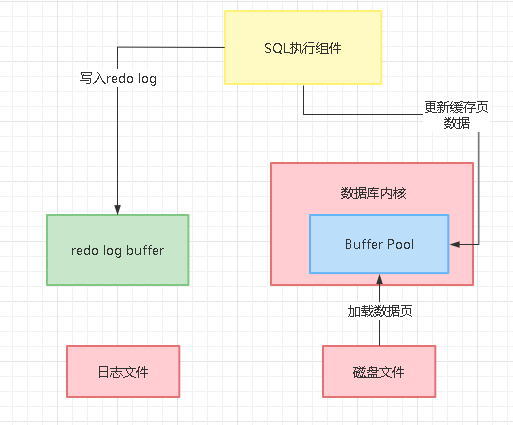
既然我们更新了Buffer Pool里的缓存页,缓存页就会变成脏页,之所以说他是脏页,就是因为缓存页里的数据目前跟磁盘文件里的数据页的数据是不一样的,所以此时叫缓存页是脏页。
既然是脏页,那么就必然得有一个合适的时机要把那脏页给刷入到磁盘文件里去,之前我们其实就仔细分析过这个脏页刷入磁盘的机制,他是维护了一个lru链表来实现的,通过lru链表,他知道哪些缓存页是最近经常被使用的。
那么后续如果你要加载磁盘文件的数据页到buffer pool里去了,但是此时并没有空闲的缓存页了,此时就必须要把部分脏缓存页刷入到磁盘里去,此时就会根据lru链表找那些最近最少被访问的缓存页去刷入磁盘,如下图所示:
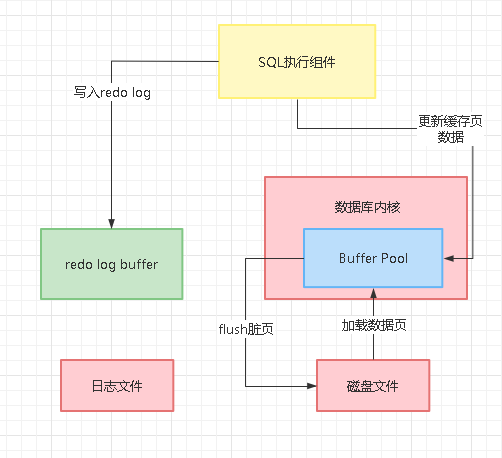
那么万一要是你要执行的是一个查询语句,需要查询大量的数据到缓存页里去,此时就可能导致内存里大量的脏页需要淘汰出去刷入磁盘上,才能腾出足够的内存空间来执行这条查询语句。
在这种情况下,可能你会发现突然莫名其妙的线上数据库执行某个查询语句一下子性能出现抖动,平时只要几十毫秒的查询语句,这次一下子要几秒都有可能,毕竟你要等待大量脏页flush到磁盘,然后语句才能执行。
另外还有一种脏页刷盘的契机,就是redo log buffer里的redo log本身也是会随着各种条件刷入磁盘上的日志文件的,比如redo log buffer里数据超过容量的一定比例了,或者是事务提交的时候,都会强制buffer里的redo log刷入磁盘上的日志文件。
然后我们也知道,磁盘上是有多个日志文件的,他会依次不停的写,如果所有日志文件都写满了,此时会重新回到第一个日志文件再次写入,这些日志文件是不停的循环写入的,所以其实在日志文件都被写满的情况下,也会触发一次脏页的刷新。
因为假设你的第一个日志文件的一些redo log对应的内存里的缓存页的数据都没刷新到磁盘上的数据页里去,那么一旦你把第一个日志文件里的这部分redo log覆盖写了别的日志,那么此时万一你数据库崩溃,是不是有些之前更新过的数据就丢失了。
所以一旦把所有日志文件写满了,此时重新从第一个日志文件开始写的时候,他会判断一下,如果要是你第一个日志文件里的一些redo log对应之前更新过的缓存页,迄今为止都没刷入磁盘,那么此时必然是要把那些马上被覆盖的redo log更新的缓存页都刷入磁盘的。
尤其是在一种刷脏页的情况下,因为redo log所有日志文件都写满了,此时会导致数据库直接hang死,无法处理任何更新请求,因为执行任何一个更新请求都必须要写redo log,此时你需要刷新一些脏页到磁盘,然后才能继续执行更新语句,把更新语句的redo log从第一个日志文件开始覆盖写。
所以此时假设你在执行大量的更新语句,可能你突然发现线上数据库莫名其妙的很多更新语句短时间内性能都抖动了,可能很多更新语句平时几毫秒就执行好了,这次要等待1秒才能执行完毕。
因此遇到这种情况,比必须要等待第一个日志文件里部分redo log对应的脏页都刷入磁盘了,才能继续执行更新语句,此时必然会导致更新语句的性能很差。
综上所述,导致线上数据库的查询和更新语句莫名奇妙出现性能抖动,其实就很肯恩是上述两种情况导致的执行语句时大量脏缓存页刷入磁盘,你要等待他们刷完磁盘才能继续执行导致的。
导致整个问题的根本原因还是两个:
第一个,可能buffer pool的缓存页都满了,此时你执行一个SQL查询很多数据,一下子要把很多缓存页flush到磁盘上去,刷磁盘太满了,就会导致你的查询语句执行的很慢。
因为你必须等很多缓存页都flush到磁盘了,你才能执行查询从磁盘把你需要的数据页加载到buffer pool的缓存页里来。
第二个,可能你执行更新语句的时候,redo log在磁盘上的所有文件都写满了,此时需要回到第一个redo log文件覆盖写,覆盖写的时候可能就涉及到第一个redo log文件里有很多redo log日志对应的更新操作改动了缓存页,那些缓存页还没flush到磁盘,此时就必须把那些缓存页flush到磁盘,才能执行后续的更新语句,那么这么一等待,必然会导致更新执行的很慢了。
所以上述两个场景导致的大量缓存页flush到磁盘,就会导致莫名其妙的SQL语句性能抖动了。
10 上亿数据量的用户表如何进行水平拆分
任何一个互联网公司都会有用户中心,这个用户中心就是负责这家公司的所有用户的数据管理,包括了用户的数据存储,用户信息的增删改查,用户的注册登录之类的。所以说互联网公司的用户数据一般都是极为庞大的,所以这种级别的用户表要如何进行水平拆分呢?
首先,一般面对这么一个几千万级的数据,刚开始可能都是把数据放在MySQL的一个单库单表里的,但是往往这么大量级的数据到了后期,会搞得数据库查询速度很慢,因为数据量级太大了,会导致表的索引很大,树的层级很高,进而导致搜索性能下降,而且能放内存缓存的数据页是比较少的,所以说,往往我们都建议MySQL单表数据量不要超过1000万,最好是在500万以内,如果能控制在100万以内,那是最佳的选择了,基本单表100万以内的数据,性能上不会有太大的问题,前提是你要建好索引,其实保证MySQL高性能通常没什么特别高深的技巧,就是控制数据量不要太大,另外就是保证你的查询用上了索引, 一般就没什么问题。
针对这个问题,我们就可以分库分表了,可以选择把这个用户大表拆分为100张表,那么此时几千万的数据分散到100个表里,类似user_001、user_002、user_100这样的100个表,每个表也就几十万数据而已。
其次,可以把这100个表分散到多台数据库服务器上去,此时要分散到几台服务器呢?要考虑两点,一个是数据量有多少个GB/TB,一个是针对用户中心的并发压力有多高。实际上一般互联网公司对用户中心的压力不会高的太离谱,因为一般不会有很多人同时注册/登录、或者同时修改自己的个人信息,所以这块并发不是太大问题。
至于数据量层面的话,根据经验来说,一般一亿行数据,大致在1GB到几个GB之间的范围,这个跟你一行数据有多少字段也有关系,大致就是这个范围,所以你几千万的用户数据,往往也就几个GB而已。这点数据量,对于服务器的存储空间来说,完全没压力。
所以综上所述,此时你完全可以给他分配两台数据库服务器,放两个库,100张表均匀的分散在2台服务器上就可以了,分的时候需要指定一个字段来分,一般来说会指定userId,根据用户id进行hash后,对表进行取模,路由到一个表里去,这样可以让数据均匀分散。
到此就搞定了用户表的分库分表,你只要给系统加上数据库中间件技术,设置好路由规则,就可以轻松的对2个分库上的100张表进行增删改查的操作了,平时针对某个用户增删改查,直接对他的userId进行hash,然后对表取模,做一个路由,就知道到哪个表里去找这个用户的数据了。
但是有一个问题,就是用户在登录的时候,可能不是根据userId登录的,可能是根据username之类的用户名,手机号之类的来登录,此时你又没有userId,怎么知道去哪个表里找这个用户的数据判断是否能登录呢?
这个问题一般来说常规方案是建立一个索引映射表,就是搞一个表结构为(username, userid)的索引映射表,把username和userid一一映射,然后针对username再做一次分库分表,把这个索引映射表可以拆分为100个表分散在两台服务器里。
用户登录的时候,根据username先去索引映射表里查找对应的userId,接着根据userId进行hash取模,然后路由到按照userId分库分表的一个表里去,就可以找到用户的完整的数据了。
如果在公司运营团队了,有一个用户管理模块,需要对公司的用户按照手机号、住址、年龄、性别、职业等各种条件进行极为复杂的搜索,这该怎么办呢?其实没有太多好办法, 基本上就是要对你的用户数据表进行binlog监听,把你要搜索的所有字段同步到Elasticsearch里去,建立好搜索的索引。然后运营系统就可以通过ElasticSearch去进行复杂的多条件搜索,然后定位到一批userId,通过userId回到分库分表环境里去找出具体的用户数据即可。
【MySQL】二十、MySQL数据库生产环境应用经验分享(四)